为什么要学习 C 语言
为什么要学习C 语言?
C 语言是无可替代的存在,有些事情只能是C 语言来完成,比如写操作系统。
学习C 语言的目的并不是精通C,而是理解C 语言的编译过程及内存变化的原理,使用C 去练习各种数据结构。
这些才是学习C 语言的目的。
快速上手
工欲善其事必先利其器,编写 C语言程序的工具非常多:
- VSCode
- Sublime Text
- CLion
- Xcode
- Qt Creator
根据个人喜好进行选择,前期入门建议使用轻量级的 IDE,这里我选择的是 VSCode。
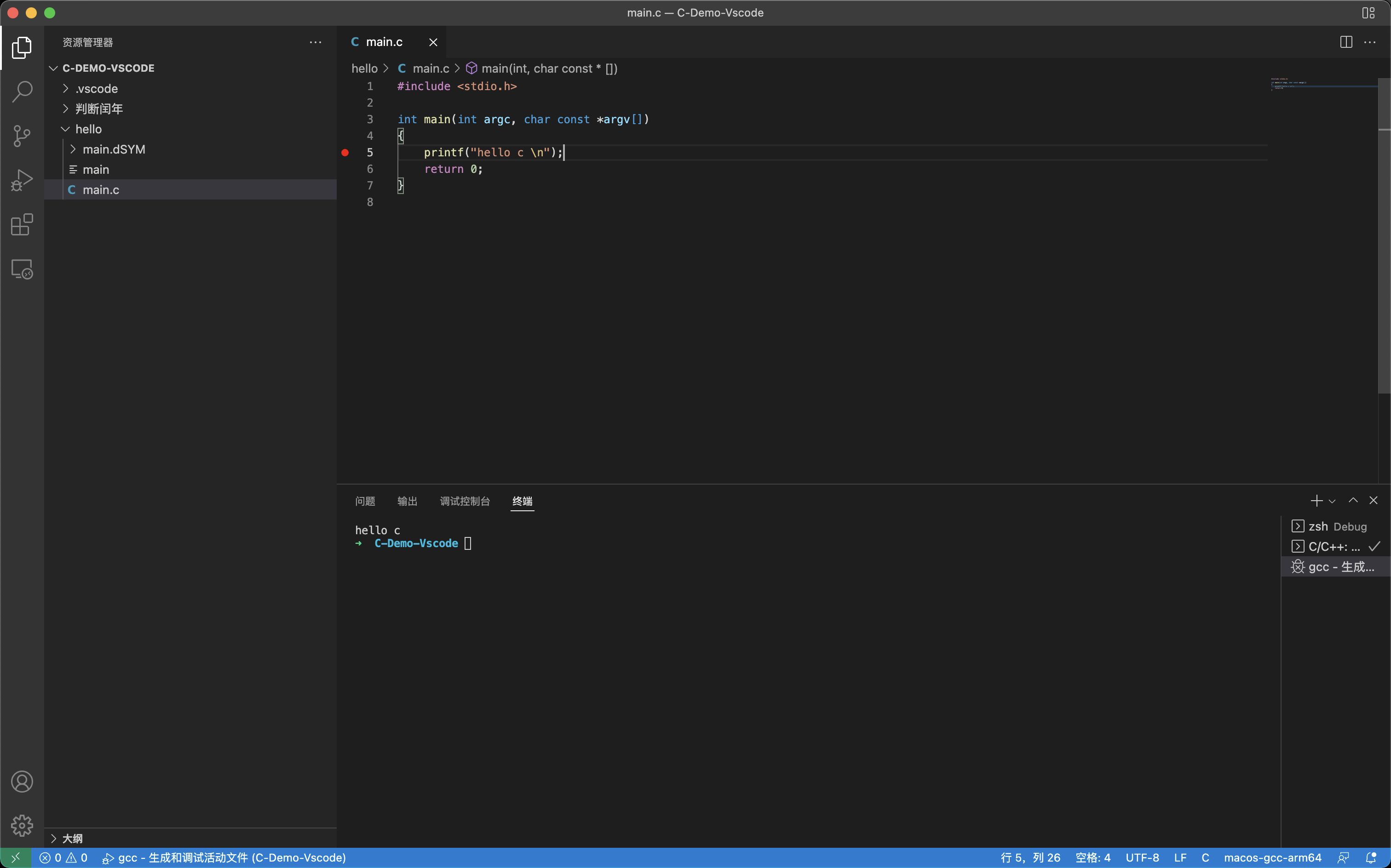
.vscode:基于当前工作区生成的配置文件目录,其中主要包含以下文件:
tasks.json:编译器构建设置launch.json:调试器设置c_cpp_properties.json:编译器路径和IntelliSense设置
每次创建一个新的项目(Demo),建议创建一个目录,因为每次编译运行.c 文件,都会额外生成一些文件:
main:对应的可执行文件main.dsYM:Xcode 生成的文件
运行
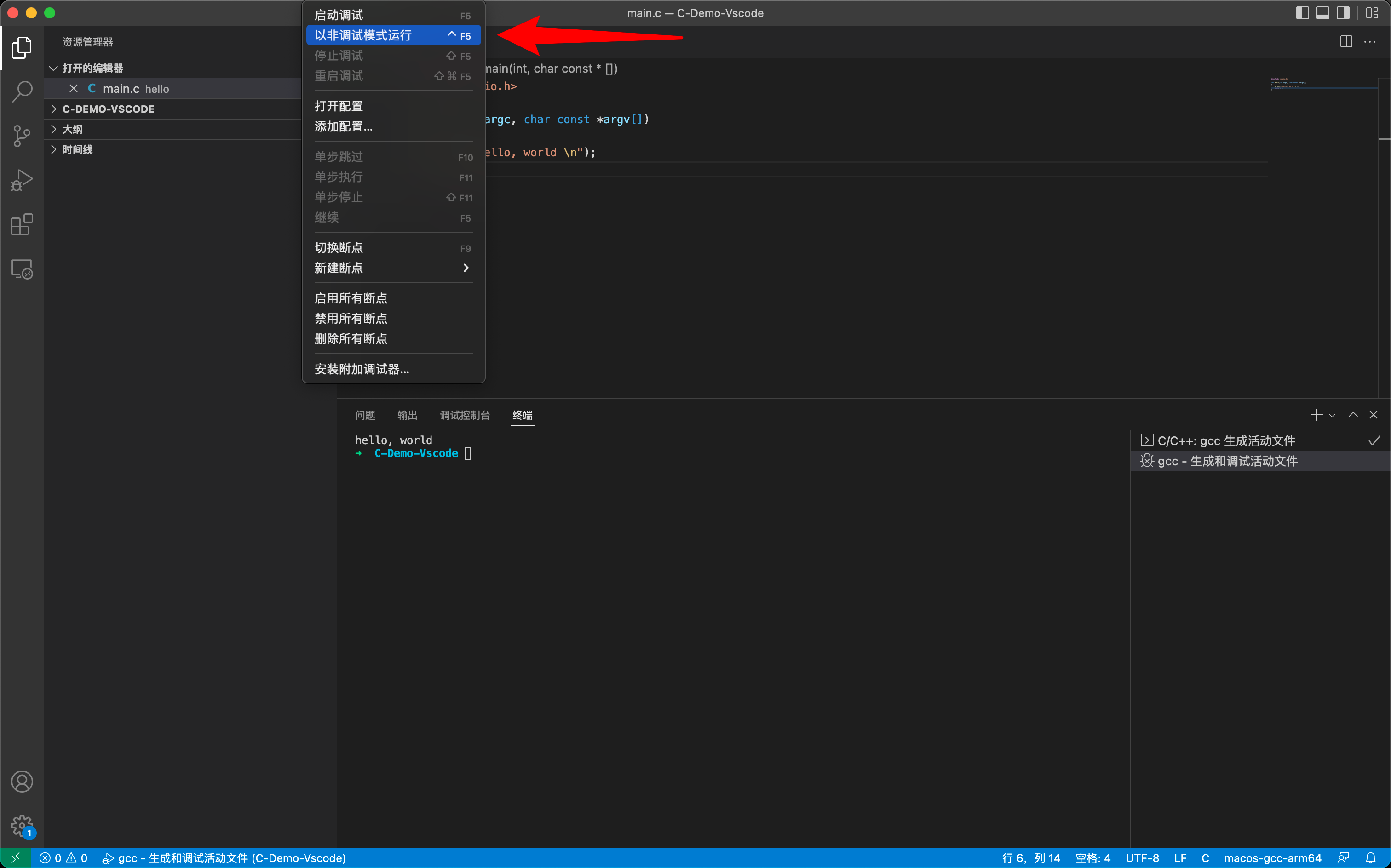
正式开始之前,确保本地环境已经安装了 gcc 或者其他编译器。
使用 VSCode 运行 C程序非常简单,只需要在对应的 C文件下点击运行或者使用 ^F5即可。
调试
在正式开始调试之前,需要先安装一个扩展:
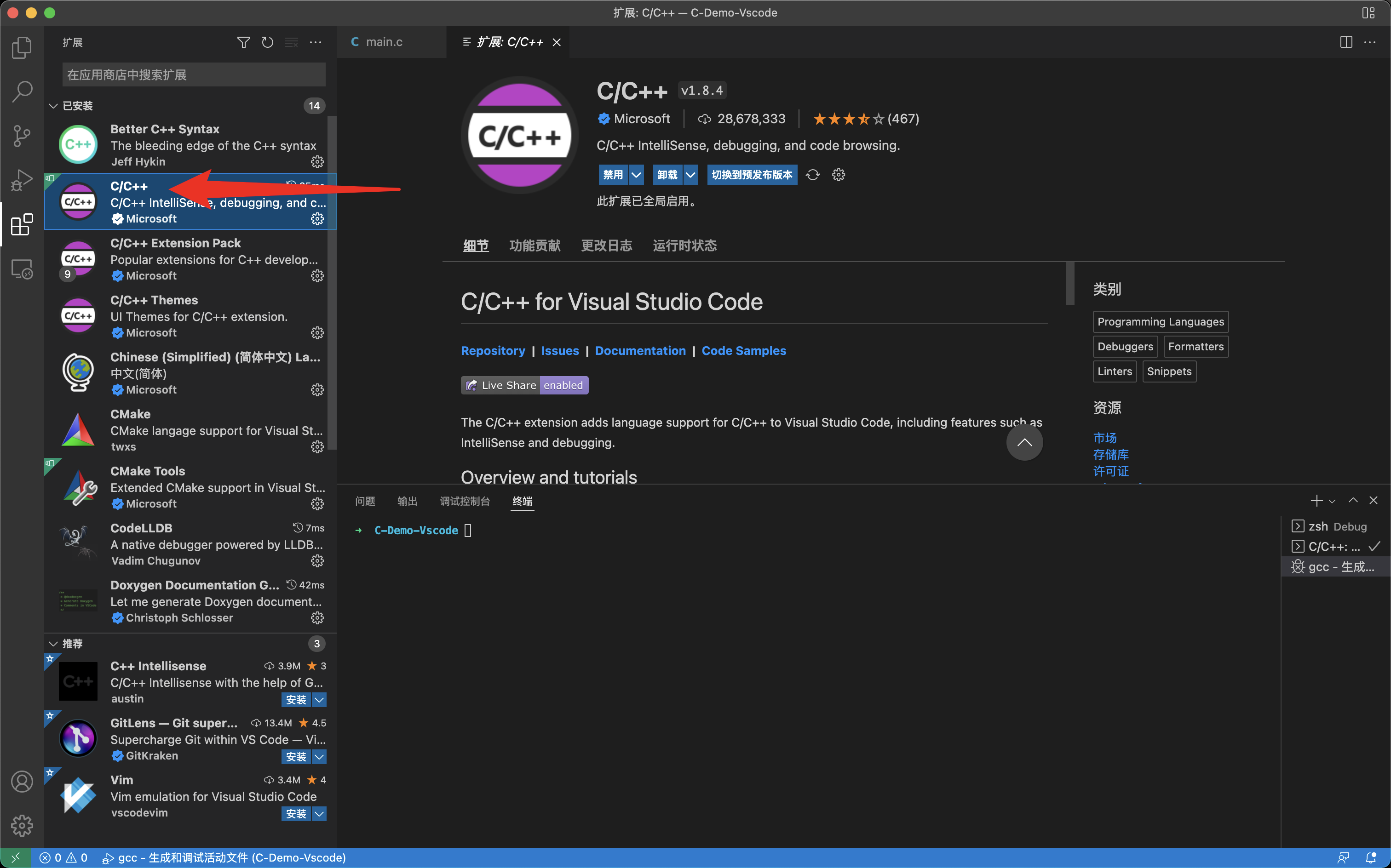
安装完成之后,将 launch.json 中的 type 配置项改为 lldb,其他部分不用做修改
1 | { |
这个表示选择对应的调试器,刚才安装的 C/C++ 就是一个调试器
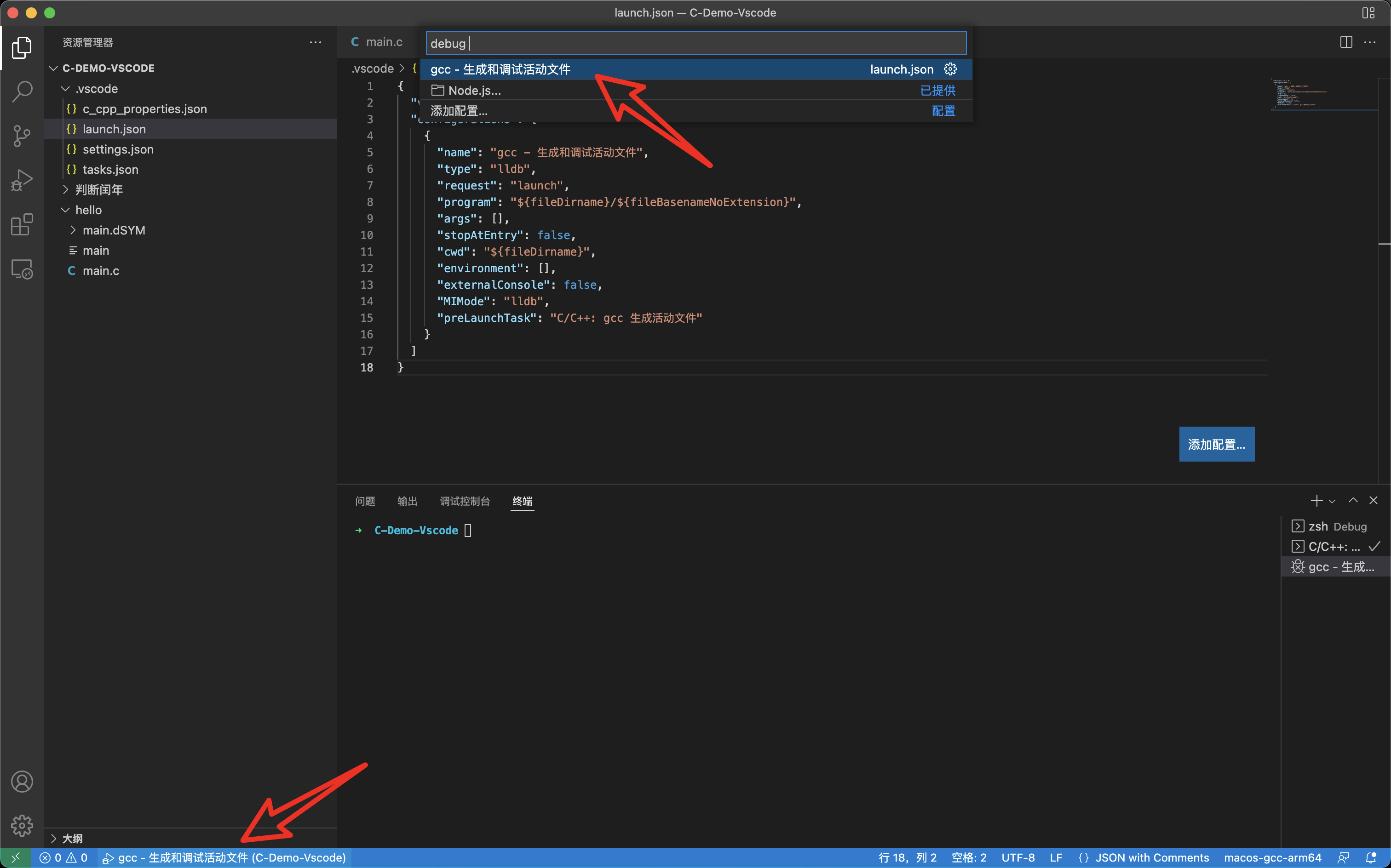
调试程序非常简单,只需要在对应代码的前面加上断点,然后点击调试即可。
从源文件到可执行文件
仅仅只靠编译是没有办法得到可执行文件的,编译器编译仅仅只是得到了本地文件,最终想到得到可执行文件,还需要进行“链接”处理。
编译
在Windows 下,编译后生成的并不是exe文件,而是扩展名为.obj 的目标文件; 在Unix 下,编译后生成的并不是可执行文件,而是扩展名为.o 的目标文件。
这些文件无法执行运行,因为编译过只是检查语法(函数、变成声明)是否正确。
在Mac 下编译main.c 文件:
1 | gcc -c main.c |
链接
找到所要用到的函数所在的目标文件并结合,最终生成一个可执行文件的过程就是链接。执行链接的程序被成为链接器。
在Mac 下链接 main.c 文件:
1 | gcc main.o -o main |
将编译、链接合并成一步:
1 | gcc main.c |
总结:
main.c:源代码文件main.o:源代码文件通过编译之后生成的本地代码(机器语言)main:可执行文件a.out:可执行文件(默认名称)
数据类型
在C 语言中,数据类型大致可以分为以下几种:
- 基本类型:整型、字符型、浮点型
- 构造类型:数组类型、结构类型、联合类型、枚举类型
- 指针类型
- void 类型
整数类型
| 类型 | 存储大小 | 值范围 |
|---|---|---|
| char | 1 字节 | -128 到 127 或 0 到 255 |
| unsigned char | 1 字节 | 0 到 255 |
| signed char | 1 字节 | -128 到 127 |
| int | 2 或 4 字节 | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| unsigned int | 2 或 4 字节 | 0 到 65,535 或 0 到 4,294,967,295 |
| short | 2 字节 | -32,768 到 32,767 |
| unsigned short | 2 字节 | 0 到 65,535 |
| long | 4 字节 | -2,147,483,648 到 2,147,483,647 |
| unsigned long | 4 字节 | 0 到 4,294,967,295 |
浮点类型
| 类型 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|
| float | 4 字节 | 1.2E-38 到 3.4E+38 | 6 位有效位 |
| double | 8 字节 | 2.3E-308 到 1.7E+308 | 15 位有效位 |
| long double | 16 字节 | 3.4E-4932 到 1.1E+4932 | 19 位有效位 |
需要注意的是,各种类型的存储大小与系统位数有关,但目前通用的以64位系统为主。
在 C 语言中,通过取地址符(&) 即可看见变量在内存所占空间大小。
C 语言中的数据类型:
- 字符型常量:用单引号括起来的一个字符,如果用双引号或者单引号内有N 个字符,则都不是字符型常量。
- 字符串常量:用双引号括起来的字符序列
在C 语言中,并没有对应的字符串变量,不会像PHP 语言专门有一个String 类型来存储对应的字符变量。
那么该如何存储字符串呢?
在C 语言中,是通过字符数组来存储字符串的。
字符串是由字符组成的,对于计算机而言,字符串是由一个个字符组成的,而一个字符的大小是一个字节。
China 这个字符串在计算机中,所占的大小是六个字节而不是五个,这是因为最后一个字符是由\0 结尾,也需要占用一个字节。
类型转换
C 语言在做混合运算时,因为是强类型的语言,当做算术运算时,C 语言会按照变量的数据类型去进行运算。
在以下示例中,如果直接进行运算,得到的结果并不是我们所期望的:
1 | int main |
所以为了能正常输出 2.5,需要将这个表达式给转换为为浮点型。
1 | int main |
再来看另外一个例子:
1 |
|
为什么得到的结果不是 3 ,而是 2?
这是因为C 语言,对于没有声明为变量的浮点型会默认转换为 double 双精度类型:
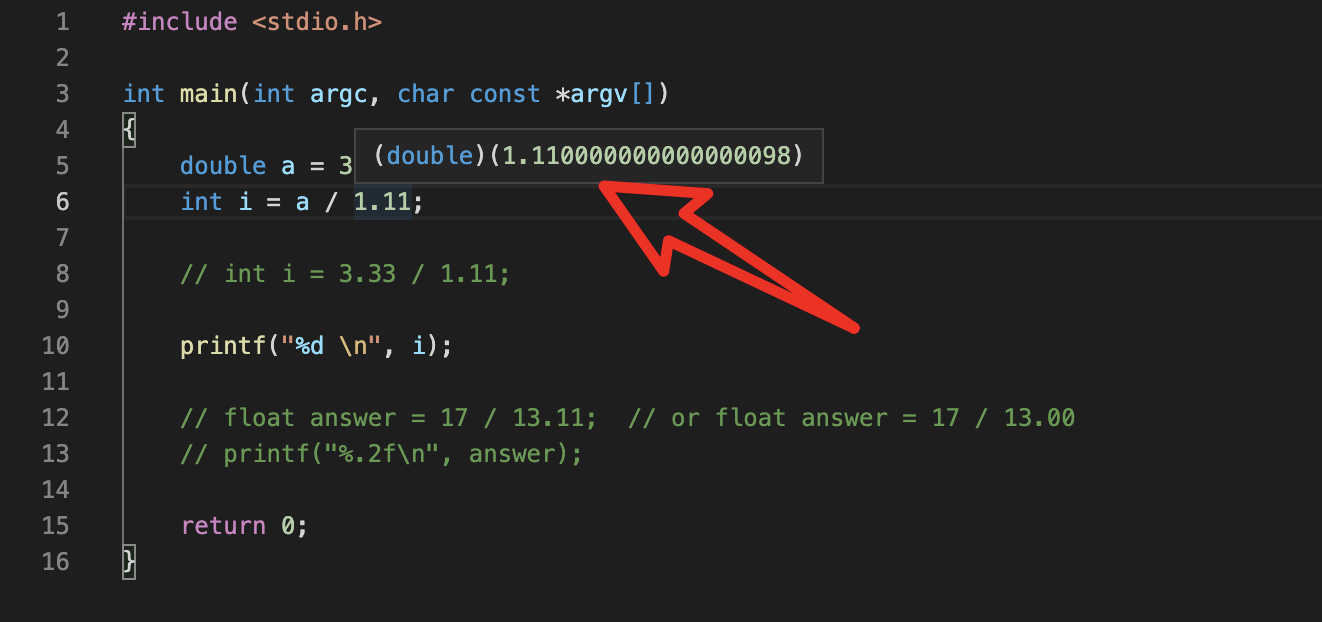
而如果另一个变量的并不是浮点类型,比如是 float 类型,此时这两个精度不一样的浮点数直接进行运算就会丢失精度。
所以呢,在C 语言中进行算术运算时,需要保证数据类型在预期内。
对于上面的问题,有两种方案:
- 将变量a 转换为
double类型 - 将 1.11 强制转换为
float类型
运算符与表达式
运算符的种类:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 条件运算符
- 逗号运算符
- 指针运算符
- 求字节数运算符
- 强制类型转换运算符
- 分量运算符
- 下标运算符
- 其他(如函数调用运算符)
i++ 和 ++i 的区别:
i++是先进行运算符,最后才对变量 i 进行+1++i则刚好是相反的,先对变量 i 进行+1,然后进行其他运算
1 |
|
C 语言中没有布尔类型。
C 语言认为一切非零的值都是真。
下面这段代码这样写是有问题的,因为 char 类型所占空间大小是一个字节,而 scanf 获取标准输入的是一个整型,而整型所占空间大小又是四个字节,所以这段代码运行之后会报错。
1 |
|
正确的实例,应该是这样,定义变量时,使用 int 类型去定义
1 |
|
获取输入与输出
scanf
整型、浮点型、字符型需要使用取地址符。
printf
printf 函数:
%d:以整型输出对应数据%f:以浮点型输出对应数据%c:以字符型输出对应数据
gets
当一次读取一行内容时,可以使用 gets
1 | char c[20]; |
使用 scanf 获取标准输入时,会遇到一个问题,当输入的字符中间存在空格时,会结束匹配,这样就没有办法把一行带有空格的字符串存到一个字符数组中了。
gets 的原理:
会从缓冲区中一直进行读取,直到遇到 \n 结束符。
而 scanf 则会匹配 \n 结束符之前的所有内容,也就是它会把 \n 结束符留在缓冲区中。所以当 scanf 和 gets 函数一起使用时,需要主动去掉结束符。
1 |
|
否则 gets 获取不到标准输入。
puts
输出字符串。
1 | puts()、 |
数组
C 语言的数组。
使用C 语言的数组时,需要注意哪些问题?
- 数组访问越界的问题
- C 语言会对字符串常量,自动增加一个
\0,所以当使用数组存在字符串常量时,需要注意数组的索引长度
字符串为什么需要有结束符?
因为需要有一个结束符,能让C 语言知道这个字符在什么位置结束。
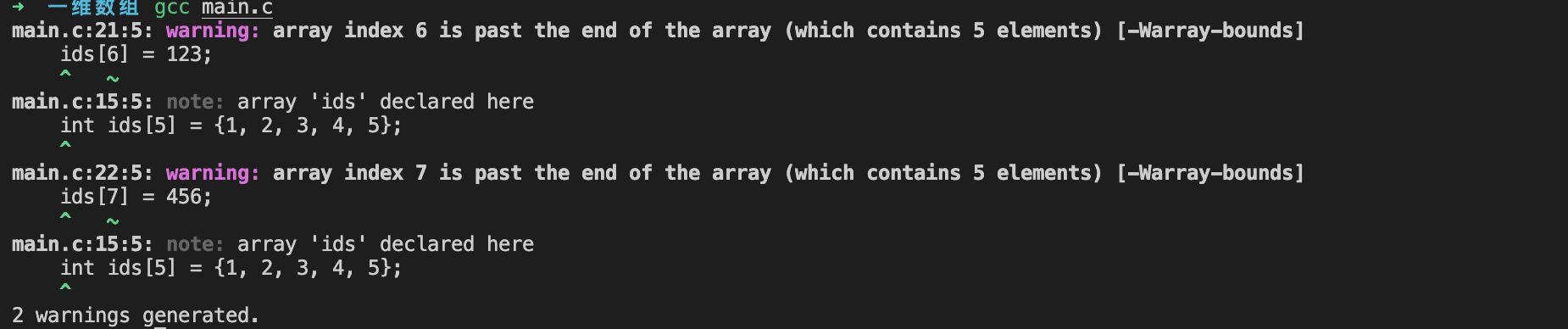
在Mac 下,数组一旦越界了,编译会过不了。
C 语言规定字符串的结束标记为 \0,系统会对字符串常量自动加一个 \0,所以字符数组存储的字符串长度必须比字符数组少 1 字节。
整型数组在传递实参时,需要一并把数组的长度给传过去。
而字符数组则不用,
函数
每一个函数在执行完成之后,都会被栈空间释放掉。
函数间的调用关系是,由主函数调用其他函数,其他函数之间也可以相互调用,同一个函数可以被一个或者多个函数调用 N 次。
函数的声明与定义是有区别的:
- 函数的定义是指对函数功能的确立,包括指定函数名、函数值类型、形参及其类型、函数体等,它是一个完整的、独立的函数单位。
- 函数的声明的作用是把函数的名字、函数类型及形参的类型、个数和顺序通知编译系统,以便在调试该函数时编译系统能正确识别函数并检查调用是否合法
C 语言的局部变量、全局变量和其他语言是很像的,没有太多需要注意的地方,只是在 C 语言中尽量不要使用全局变量,程序容易出错。
获取字符数组的索引长度使用 sizeof,获取字符数组的字符长度使用 strlen。
遍历一个字符数组时,尽管输出的是 1,但要明确它是一个字符类型,而不是整型。
所以在进行比较时,需要时刻保证等式两边的数据类型是一致的。
1 |
|
在做 C 语言字符串拼接、替换相关的题目时,需要注意使用 \0 作为结束符。
scanf 会从缓冲区中读取对应的内容,直至遇到 \n 才会停止读取,不会读取 \n。
而 gets 函数也是从缓冲区里面读取,遇到 \n 就结束。
所以使用完 scanf 之后,如果不主动消除 \n,直接使用 gets 会导致程序直接向下继续执行,因为 gets 读取到的是结束符 \n。
指针
指针的本质就是地址。
一个变量在内存中,可以分为两部分:编址(变量的地址)和具体的值。
如果想把某个变量的地址保存下来,就需要用到指针。
& 是取地址符号,也称为引用,通过该操作符可以获取一个变量的地址值。* 是取值操作符,也称为解引用,通过这个操作符可以获取一个地址对应的数据。
指针的使用场景总结下来只有两种:
- 传递
- 偏移
函数具有自己的内存空间,在某个函数中定义了一个变量之后,就会在这个内存中开辟对应大小的内存空间。
值传递是不会改变原值的。
& 符号的作用是获取变量的地址,* 符号的作用是通过变量的地址获取对应的值。
1 |
|
字符数组的数组名里存的就是字符数组的起始地址。类型是字符指针。
数组名的类型是数组,里面存了一个值,就是数组的起始地址,
指针的传递
1 |
|
指针的偏移
1 |
|
指针与一维数组
数组在传递时会弱化为指针:
1 |
|
一维数组在进行函数调用时,为什么它的长度子函数没有办法知道?
这是因为一位数组的数组名存储的是数组的首地址(也就是索引为零的值的地址),压根就不是数组,所以没有办法直接知道对应长度。
1 | void change(char *d) |
为什么在子函数内部可以对数组进行访问和修改?
这里其实用到了指针的传递与偏移。
指针与动态申请内存
数组一开始定义好就确定下来了,数组是放在栈空间的。
栈空间的大小在编译时是确定的,如果使用大小不确定,那么就要使用堆空间。
申请堆空间,会把一个连续的 N 个字节的空间给你,返回的是一个起始地址。malloc 申请空间的单位是字节。
1 |
|
野指针是什么?
当一个指针指向一块空间,而这个空间又不属于它,这就是野指针。
结构体
使用结构体之前,需要先声明:
1 | struct student |
定义一个结构体变量:
1 | struct student student1 = {1001, "boo", 23}; |
定义一个结构体数组变量:
1 | struct student sarr[3] = { |
. 操作符用来访问结构体变量,-> 操作符用来访问指针的成员。
结构体指针
结构体指针就是结构体变量所占据的内存段的起始地址。
1 |
|
typedef
比如如果需要定义一个结构体变量,每次都需要写一个 struct xxx,这个显然是很麻烦的事情。
typedef 关键字的作用就是声明新的类型名来代替已有的类型名。
1 |
|
C++引用
C++ 的引用其实就是在子函数中改变主函数的某个变量的值。
C 也可以做到,只不过相比起来 C++ 的写法更简洁一些。
1 |
|
