本文是基于 极客时间——MySQL 实战 45 讲 整理的学习笔记,仅供学习参考,请勿用于商业用途,如若侵权,请联系并删除。
课程重点:
- 了解只查一行记录,也会执行得特别慢的多种情况
有时候,在 Mysql 中,只查一行记录,也会执行得特别慢。
当然上面说的这个问题,肯定不是在 MySQL 数据库本身就有很大的压力,导致数据库服务器 CPU 占用率很高或 ioutil(IO 利用率)很高,这种情况下所有语句的执行都有可能变慢。
为了便于描述,我还是构造一个表,基于这个表来说明今天的问题。这个表有两个字段 id 和 c,并且我在里面插入了 10 万行记录。
1 | CREATE TABLE `t` ( |
第一类:查询长时间不返回
如下图所示,在表 t 执行下面的 SQL 语句:
1 | select * from t where id=1; |
查询结果长时间不返回。
一般碰到这种情况的话,大概率是表 t 被锁住了。接下来分析原因的时候,一般都是首先执行一下 show processlist 命令,看看当前语句处于什么状态。
然后我们再针对每种状态,去分析它们产生的原因、如何复现,以及如何处理。
等 MDL 锁
通常前面的学习得知,MDL 锁是可能会导致整个表锁住的(增删改查都做不了)。
复现过程:
- 开启一个事务 A ,对表 t 加一个 MDL 读锁(对表 t 做增删改查)
- 开启一个事务 B,对表 t 加一个 MDL 写锁(对表 t 增加一个字段)
此时 session A 开启了事务,并没有释放,而 session B 需要 MDL 写锁,因此只能被阻塞(阻塞原因:MDL 读写锁是互斥的)
此时的解决方案就是,使用 show processlist 命令查看 Waiting for table metadata lock。

找出造成阻塞的 process id,把这个连接用 kill 命令断开即可。
等 flush
MySQL 中对表做 flush 操作的用法,一般有以下两个:
- flush tables t with read lock;
- flush tables with read lock;
这两个 flush 语句,如果指定表 t 的话,代表的是只关闭表 t;如果没有指定具体的表名,则表示关闭 MySQL 里所有打开的表。
但是正常这两个语句执行起来都很快,除非它们也被别的线程堵住了。
所以,出现 Waiting for table flush 状态的可能情况是:有一个 flush tables 命令被别的语句堵住了,然后它又堵住了我们的 select 语句。
重现步骤:
- 开启一个事务 A,执行
select sleep(1) from t,故意每行都调用一次 sleep(1),这样这个语句默认要执行 10 万秒(依据表 t 的总行数) - 开启一个事务 B,执行
flush tables t,关闭表 t,这时就需要等 session A 的查询结束 - 此时如果再开启一个事务 C,执行查询语句,就会被 flush 命令堵住了
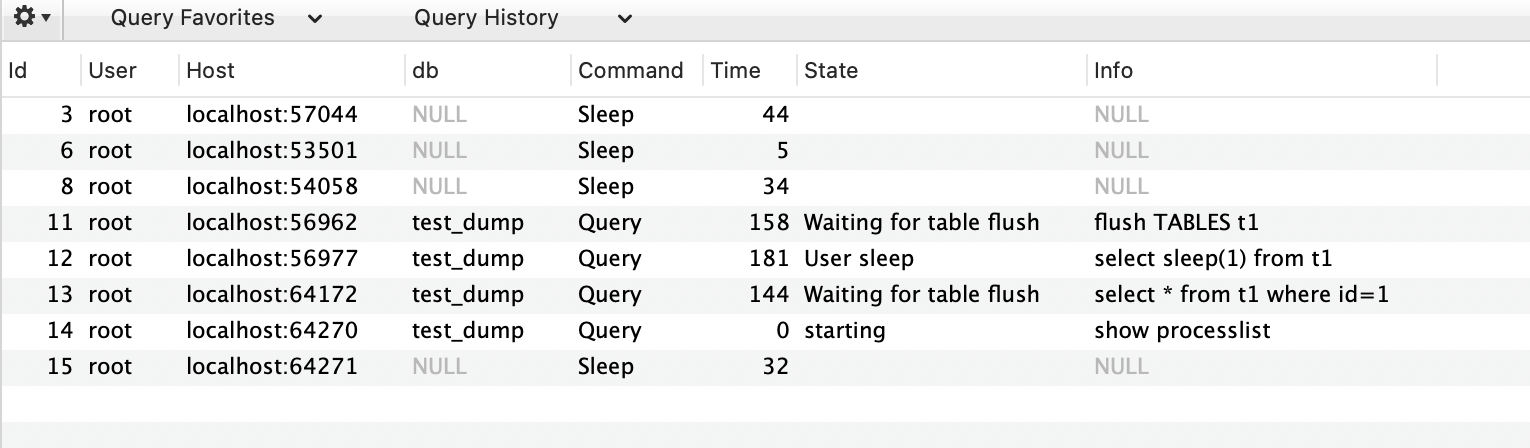
解决方案同时是,找出造成阻塞的 process id,把这个连接用 kill 命令断开即可。
等行锁
现在,经过了表级锁的考验,我们的 select 语句终于来到引擎里了。
1 | select * from t where id=1 lock in share mode; |
- lock in share mode 表示加读锁(S 锁,共享锁)
- for update 表示加写锁(X 锁,排他锁)
由于访问 id=1 这个记录时要加读锁,如果这时候已经有一个事务在这行记录上持有一个写锁,我们的 select 语句就会被堵住。
复现步骤:
- 开启一个事务 A,更新 id = 1 这一行的记录
- 开启一个事务 B,执行上面的 SQL 语句
显然,session A 启动了事务,占有写锁,还不提交,是导致 session B 被堵住的原因。
Mysql 5.7 可以通过 sys.innodb_lock_waits 表查到。
1 | select * from sys.innodb_lock_waits where locked_table= '`test_dump`.`t`'; |

通过这个命令可以得到的信息还是挺多的,找到对应的线程 id,将其 kill 掉即可。
连接被断开的时候,会自动回滚这个连接里面正在执行的线程,也就释放了 id=1 上的行锁。
第二类:查询慢
1 | select * from t where c=50000 limit 1; |
由于字段 c 上没有索引,这个语句只能走 id 主键顺序扫描,因此需要扫描 5 万行。

通过查询慢查询日志,可以确定,确实扫描了 5 万行,但是并不慢呀,2ms 就返回了。
坏查询不一定是慢查询。我们这个例子里面只有 10 万行记录,数据量大起来的话,执行时间就线性涨上去了。
扫描行数多,所以执行慢,这个很好理解。
但是接下来,我们再看一个只扫描一行,但是执行很慢的语句。
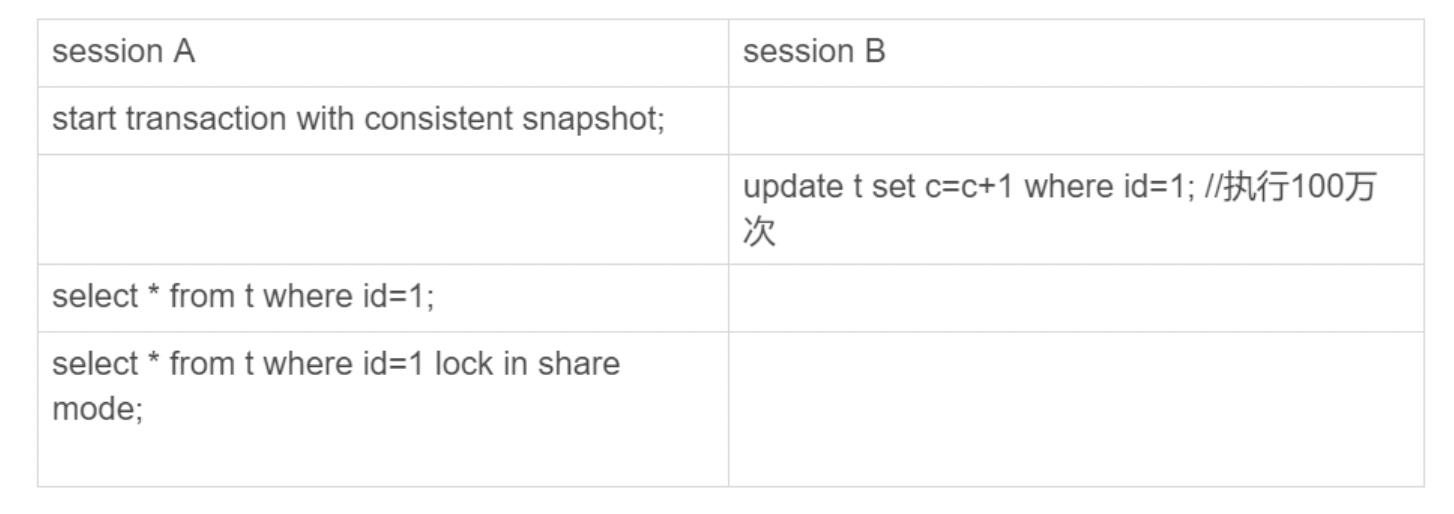
复现步骤如上图所示。
session A 先用 start transaction with consistent snapshot 命令启动了一个事务,之后 session B 才开始执行 update 语句。
session B 执行完 100 万次 update 语句后,生成了 100 万个回滚日志 (undo log)。
带 lock in share mode 的 SQL 语句,是当前读,因此会直接读到 1000001 这个结果,所以速度很快;而 select * from t where id=1 这个语句,是一致性读,因此需要从 1000001 开始,依次执行 undo log,执行了 100 万次以后,才将 1 这个结果返回。
总结
- 坏查询不一定是慢查询,当数据量大一些时,执行时间就线性涨上去了
- 表锁、行锁都可能会导致阻塞查询语句
