轮询查 Db 对服务器(数据库)的压力究竟有多大?
前段时间接手一个老系统,其中对于“订单”的处理,非常原始且简单粗暴。
直接通过一个 PHP 脚本不断轮询查询数据库,直到查找到需要处理的“订单”才去处理,否则一直查找。
1 | <?php |
类似的处理还有其他几个脚本。
因为项目的历史包袱较重,也不好做一些大调整,起初我并没有太在意,就直接部署到服务器上了。
就在最近,我收到反馈,系统有问题。通过一系列排查最后发现是因为“订单”处理不及时,“订单”堆积过多导致的一系列问题。
我寻思着,用户量也没有很多,为什么会处理不完呢?使用 glances 命令看了一眼。
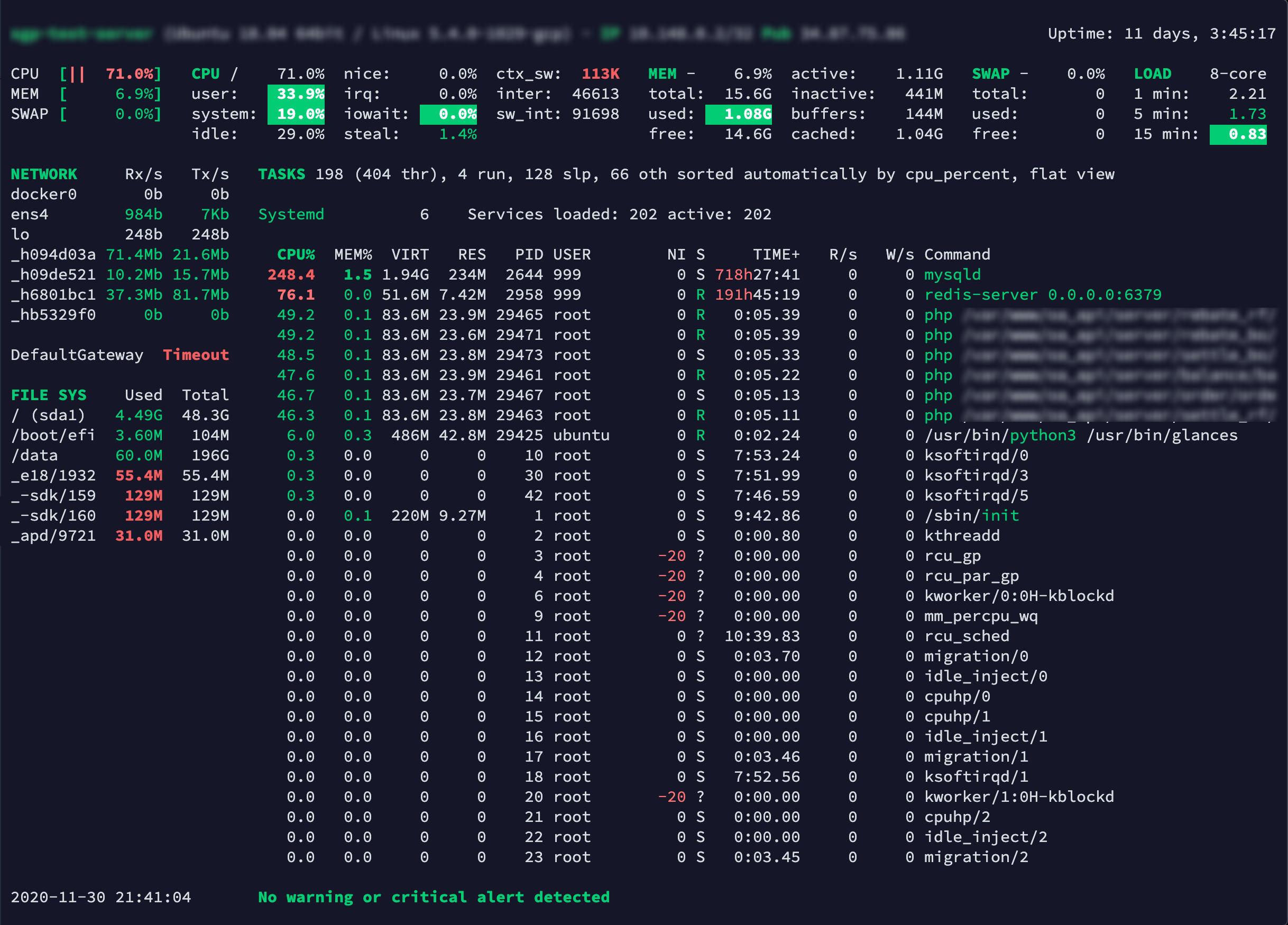
这不看不知道,一看吓一跳,CPU 直接警告了。无论多好的机器也经受不住这样折腾,赶紧把轮询查表的方式改成了查队列。
基于Redis 的List 实现一个简单的消息队列,更新到服务器之后,可以看到CPU 直接降了一半。
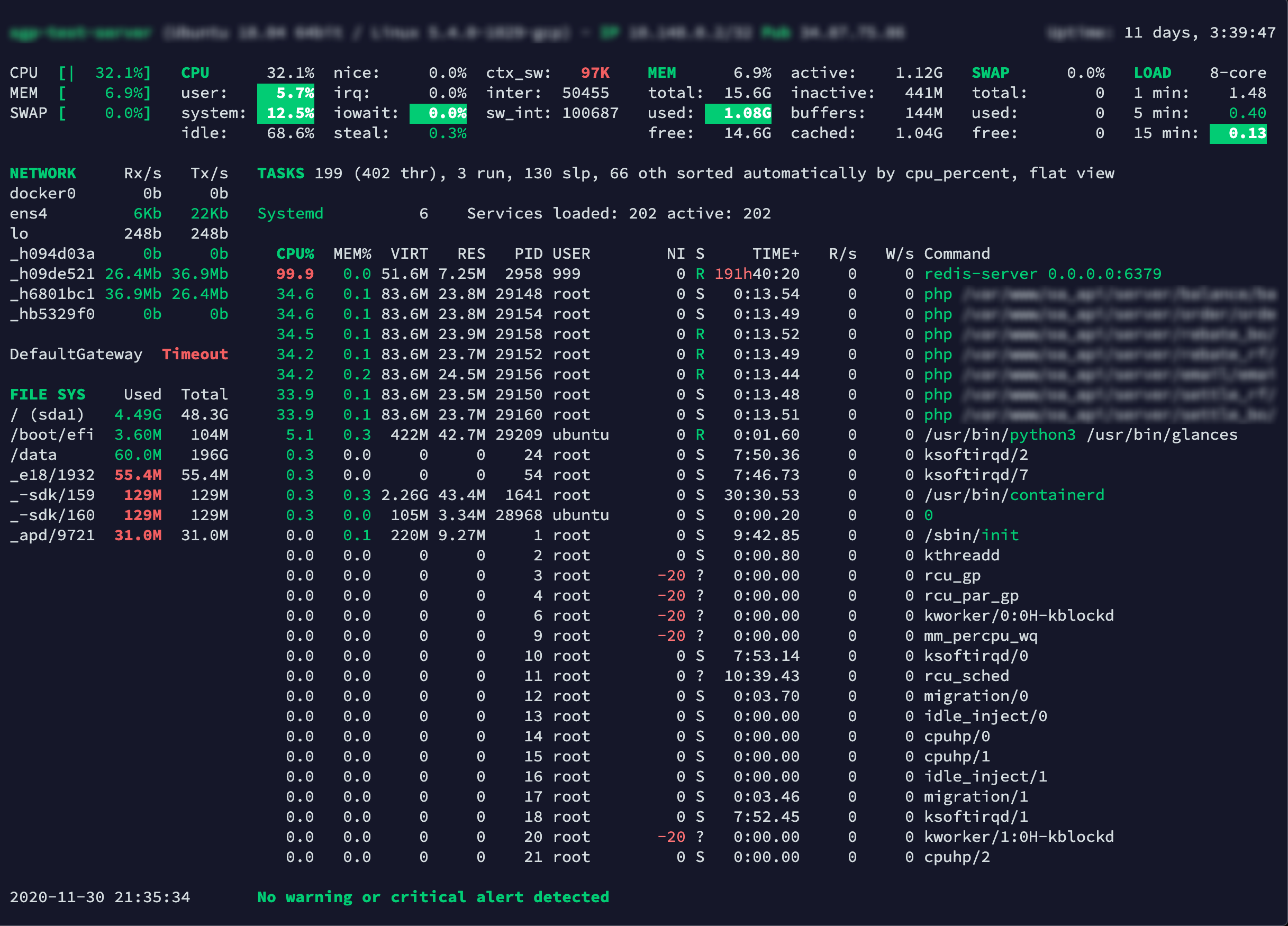
为什么使用Redis 会比Mysql 的效果要好?
通俗一点解释是因为Redis 存储是基于内存,Mysql 存储是基于磁盘,而内存的读写要比磁盘快不止一个数量级。
当然,上面的处理方式并不是最优的,这里只是单论如何发现性能瓶颈,以及如何调优这一点来进行说明。
