什么是持久化?
Redis 所有数据都是存储在内存中的,对于数据的更新将异步的保存在磁盘中,当Redis实例重启时,即可利用之前持久化的文件实现数据恢复。
主流数据库的持久化方式:
- 快照
- Mysql dump
- Redis rdb
- 日志
- Mysql binlog
- Redis aof
RDB
什么是RDB?
Redis 通过一条命令或者某种方式创建 rdb 文件,该文件是二进制格式,存储在硬盘中。
当需要对Redis 进行恢复时,就可以去加载该文件。数据恢复的程度,取决于 rdb文件(快照)产生的时刻。
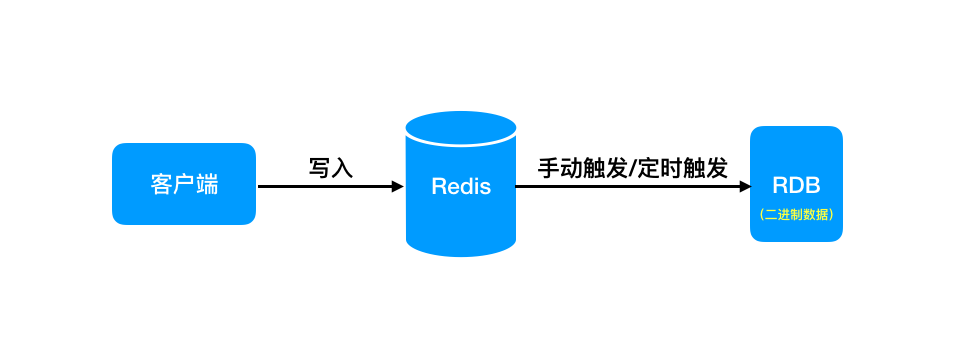
三种触发机制
Redis 生成 rdb 文件有三种方式,分别是:
- save
- bgsave
- 自动策略
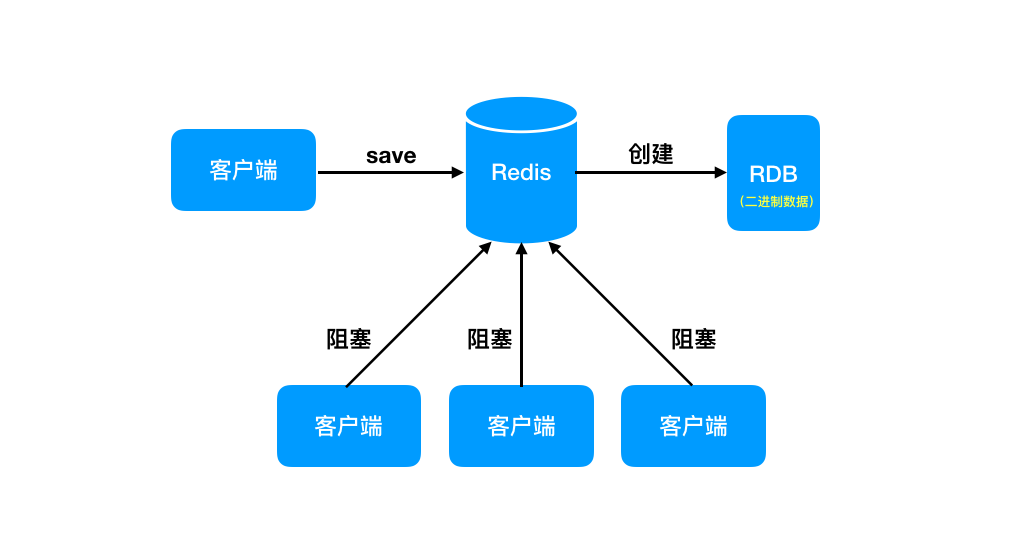
save
save 命令有如下特点:
- 同步阻塞
- 文件策略:如果存在旧的rdb 文件,则会替换成新的
- 复杂度:O(N)
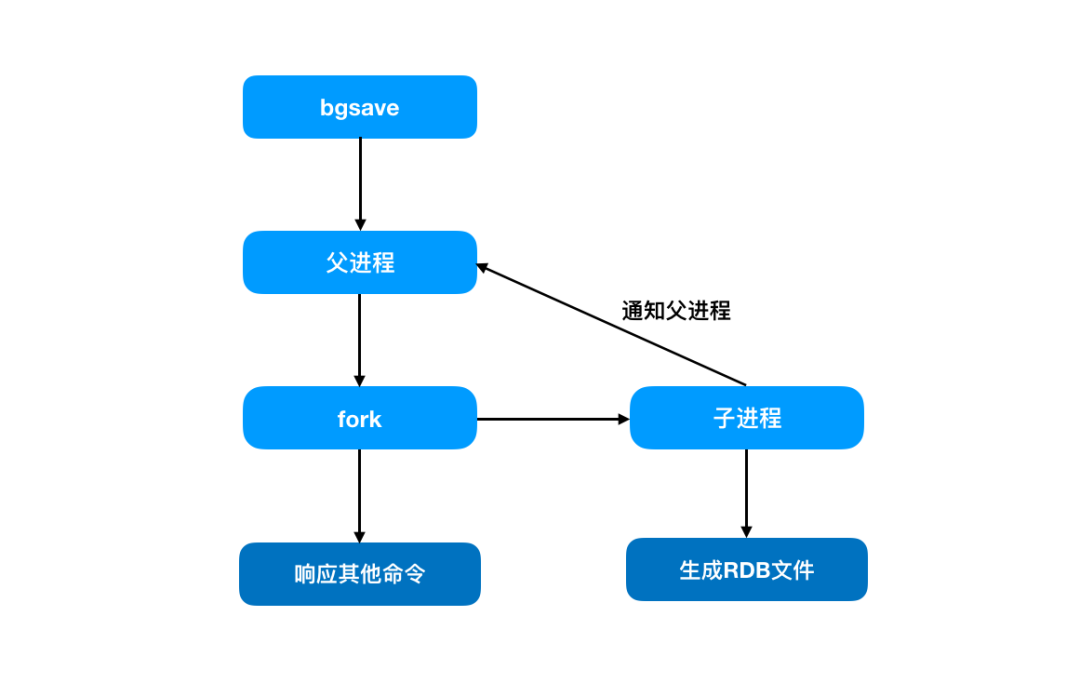
bgsave
bgsave 命令有如下特点:
- 异步非阻塞(几乎不会阻塞客户端)
- 文件策略和复杂度同上。
save 还是 bgsave?
| 命令 | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞 | 是 | 否(阻塞发生在fork() |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端 |
| 缺点 | 阻塞客户端 | 需要fork,消耗内存 |
在数据量不大的情况下,其实使用save 还是bgsave 并没有什么差异。
它俩都是需要手动执行命令才会触发机制,那么有没有自动的方式呢?答案是有的。
自动策略
自动生成策略是根据某个规则来决定是否生成 rdb 文件,这个过程也是一个bgsave 的过程。
默认策略:
|seconds|changes|
|-|-|
|900|1|
|300|10|
|60|10000|
上述配置的意思是:如果在60s 中做了10000 次改变或者在 300s 中做了 10次 改变,或者在900s 中做了 1 次改变,则均会触发bgsave。
配置
1 | #save 900 1 |
触发机制
Redis 当达到以下触发机制时,也会自动创建rdb 文件。
- 全量复制
- debug reload
- showdown
RDB 文件恢复
前面已经提到过了,持久化的目的是为了解决内存异常导致的数据丢失问题,如果真的遇到了这样的情况,RDB 文件又是如何实现数据恢复的呢?
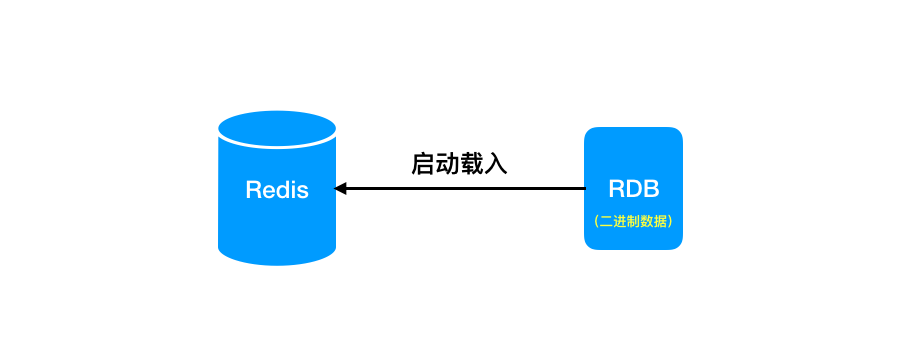
因为开启持久化之后,数据会存储到名为 dump.rdb 的文件中,当 Redis 服务器重启时,检测到 dump.rdb 文件后,就会自动加载进行数据恢复。
AOF
在正式介绍什么是AOF 之前,我们先来了解一下RDB 方式现存的问题。
- 耗时、耗性能
- 不可控、丢失数据
什么是AOF?
与RDB 不同的是,它是通过保存所执行的写命令来实现的,并且保存的数据格式是客户端发送的命令。
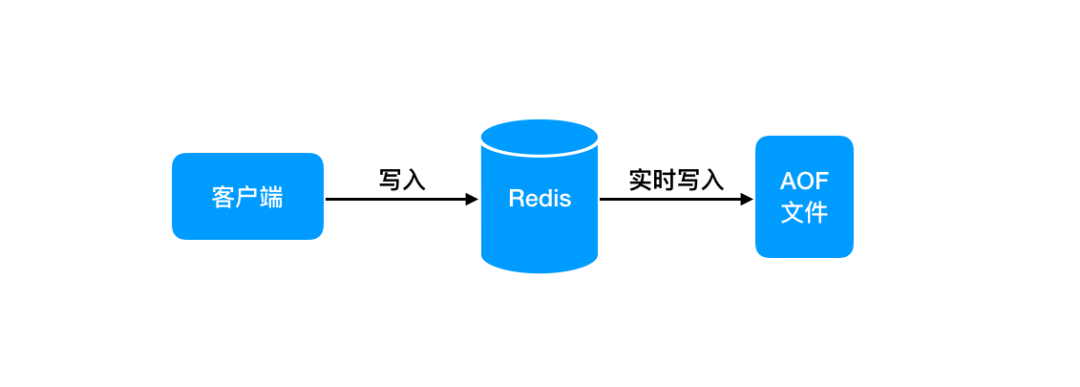
三种策略
Redis 在执行写命令时,首先写入硬盘的缓冲区,缓冲区会根据以下三种策略去刷新到磁盘中。
- always:每次写入都把缓冲区 fsync 到硬盘,性能影响最大,占用磁盘 IO 较高,数据安全性最高。
- everysec:每秒把缓冲区 fsync 到硬盘,对性能影响相对较小。
- no:由系统决定是否 fsync。
always 还是 everysec 还是 no?
| 命令 | always | everysec | no |
|---|---|---|---|
| 优点 | 不丢失数据 | 每秒一次 fsync | 不用管 |
| 缺点 | IO 开销较大,一般的sata 盘只有几百 TPS | 丢一秒数据 | 不可控 |
AOF 重写
来看这样一种情况:
1 | 127.0.0.1:6379> set name php |
虽然set 了很多次,但是name 的值,只受最后一次set 的影响,所以前面那么多次,其实没有必要也保存到AOF 文件中。
满足所设置的条件时,会自动触发 AOF 重写,此时 Redis 会扫描整个实例的数据,重新生成一个 AOF 文件来达到瘦身的效果。
配置
1 | // AOF |
AOF 文件恢复
与 RBD 文件不同,因为AOF 文件的数据格式,是由命令组成的,所以客户端直接执行每条命令就可以将数据进行恢复。
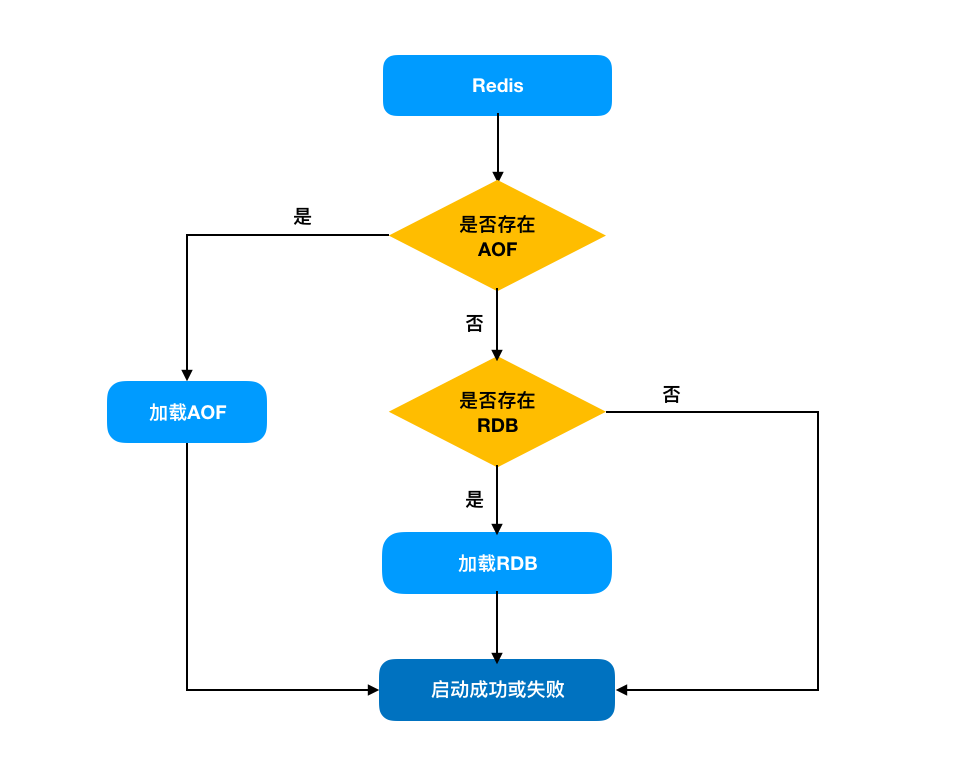
RDB 还是AOF?
RDB 和AOF 有各自的优缺点,那么到底该选择哪个呢? 并没有绝对正确的答案。需要根据实际情况去作取舍,不过通常都是使用混合持久化的方式。
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 丢数据 | 根据策略决定 |
| 级别 | 重 | 轻 |
混合持久化
混合持久化是通过 aof-use-rdb-preamble 参数来开启的。它的操作方式是这样的,在写入的时候先把数据以 RDB 的形式写入文件的开头,再将后续的写命令以 AOF 的格式追加到文件中。这样既能保证数据恢复时的速度,同时又能减少数据丢失的风险。
那么混合持久化中是如何来进行数据恢复的呢?在 Redis 重启时,先加载 RDB 的内容,然后再重放增量 AOF 格式命令。这样就避免了 AOF 持久化时的全量加载,从而使加载速率得到大幅提升。
总结
RDB持久化
- 将某一时刻的数据以二进制形式写入到磁盘里,服务重启时检测到对应文件自动加载进行数据恢复。
- 有手动触发和自动触发两种机制。
AOF持久化
- 以文件追加的方式写入客户端执行的写命令。
- 数据恢复时,通过创建伪客户端的方式执行命令,直到恢复完成。
混合持久化
- 在写入的时候先把数据以 RDB 的形式写入文件的开头,再将后续的写命令以 AOF 的格式追加到文件中。
