业务场景描述:
- 订单创建成功之后,每一笔订单都需要进行统计及其他业务处理。
- 如何及时发现处理失败的订单,然后进行补单处理。
- 订单所产生佣金的处理。
困境
该应用因为一些历史原因使用 Mysql 的数据表作为消息队列。
整个系统中有多个生产者会向该数据表中插入记录,同时有一个脚本会作为消费者去数据库中查找记录并消费。
但是这样做是存在很多问题:
- 长时间与数据库保持连接进行查询操作,消耗服务器资源。
- 在数据量较大或者延时较高的情况下,不能及时处理完,会影响其他业务。
- …
所以更好的方式应该是使用消息队列来解决。
什么是消息队列?
消息队列(Message Queue),是分布式系统中重要的组件,其通用的使用场景可以简单地描述为:
当不需要立即获得结果,但是并发量又需要进行控制的时候,差不多就是需要使用消息队列的时候。
常见应用场景
其常见的应用场景有以下几个:
- 应用耦合:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
- 异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
- 限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;
- 消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理;
1. 异步处理
场景描述:用户注册之后,需要邮箱或者短信通知,传统的做法有两种:
串行:
- 注册成功
- 发送邮件
- 发送短信
只有等以上三个任务全部完成之后,才会返回客户端。
并行:
- 注册成功
- 发送邮件并同时发送短信
虽然也是需要以上三个任务全部完成才会返回客户端,但并行与串行的区别就在于,通过使用多线程来缩短程序处理时间。
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)。并行方式处理的请求量是10次(1000/100)。
就该场景而言,如何突破传统方式带来的性能瓶颈?
解决方案:
- 引入消息队列
- 将不是必须的业务逻辑,加入队列中,进行异步处理。
2. 应用解耦
消息队列模式
消息队列包括两种模式,点对点模式(point to point, queue)和发布/订阅模式(publish/subscribe,topic)。
点对点模式
点对点模式包括以下三个角色:
- 消息队列
- 生产者
- 消费者
生产者将消息发送到队列中,消费者从队列中取出消息进行消费,消息被消费之后,消息不再被存储。

点对点模式的特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)。
- 生产者和消费者之间没有依赖性,不会因为消费者是否在线,都会存在于队列中。
发布/订阅模式
发布/订阅模式下包括三个角色:
- 频道
- 发布者
- 订阅者
发布者将消息发布在频道中,频道将消息传递给所有订阅者。
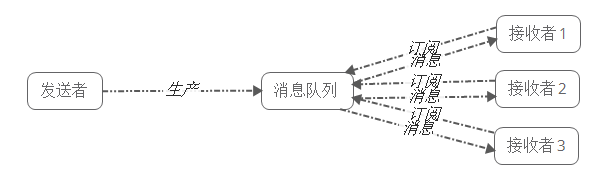
发布/订阅模式特点:
- 每个消息可以有多个订阅者
- 发布者和订阅者之间存在依赖关系,必须先订阅频道,发布者发布的消息才会被订阅者所接收。
- 因为发布的消息是无状态的,所以订阅者需要订阅频道且在线。
常见消息队列
- RabbitMQ
- ActiveMQ
- RocketMQ
- Kafka
- Redis
