这篇笔记用来记录如何从单机一步步设计出支持百万级、千万级、亿级数据的架构。
单机时代
最开始的时候,用户量很少,一天就几百上千个请求,此时一台服务器就完全足够。
Java、Python、PHP或者其他后端语言开发一个Web后端服务,再用一个MySQL来存储业务数据,它俩携手工作,运行在同一台服务器上,对外提供服务。
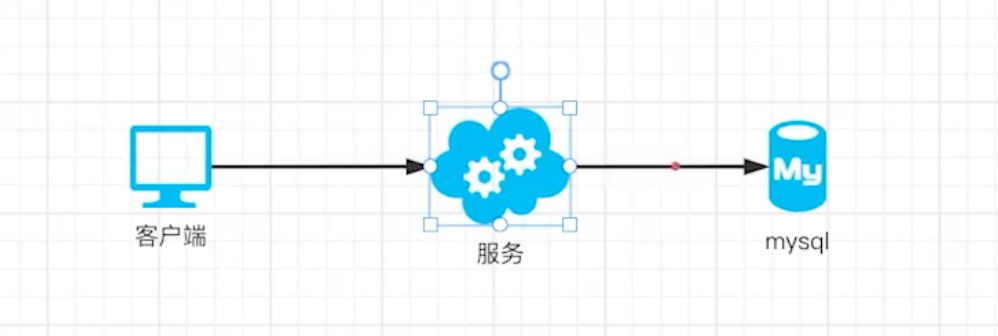
随着数据量增加、访问量增加,MySQL 会出现查询变慢,Web 服务会出现访问变慢。
解决方案:
- 创建索引和优化索引,解决查询变慢的问题。
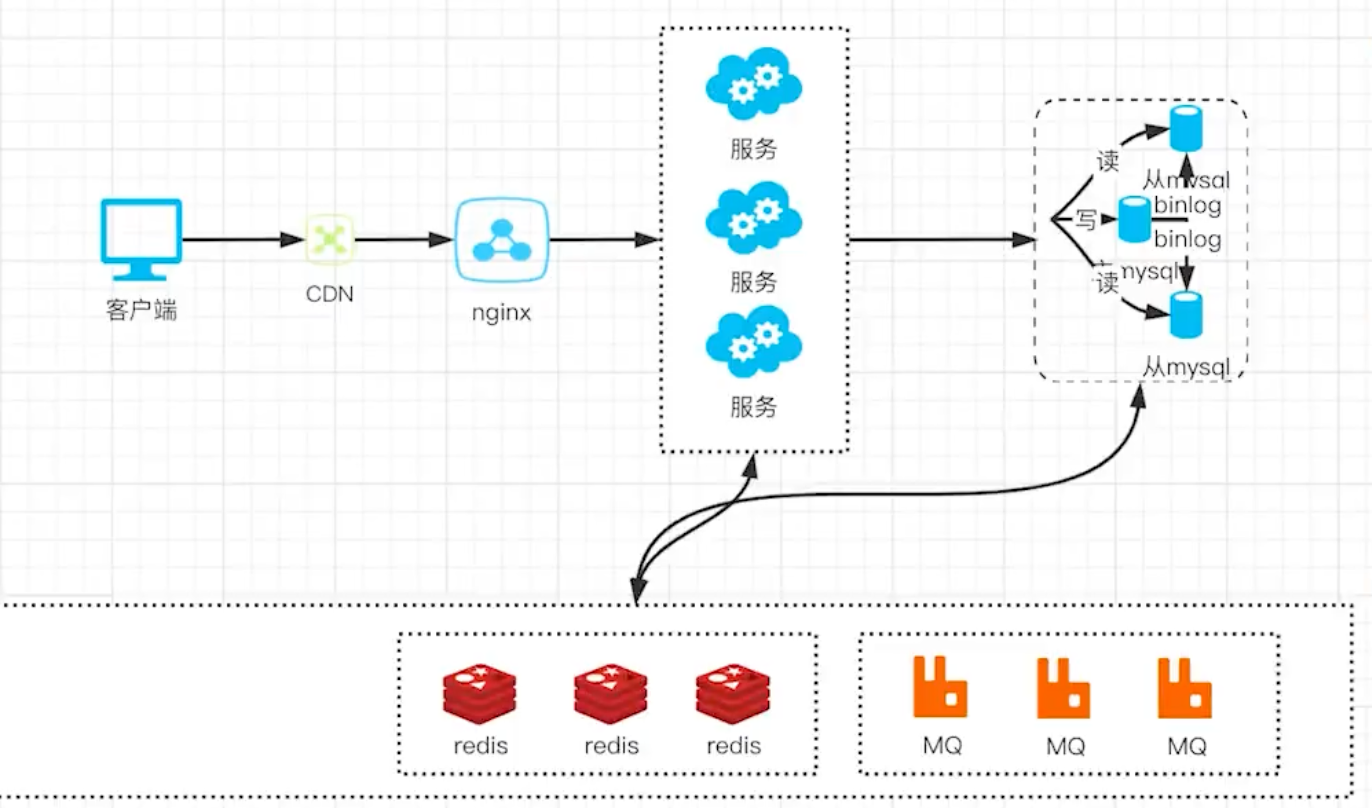
- 增加 CDN(让静态资源不至于直接请求服务器)
- 增加服务器,使用 nginx 做负载均衡(分散单台压力)
负载均衡
数据量还在继续增加,单台服务器已经不能满足需求了。
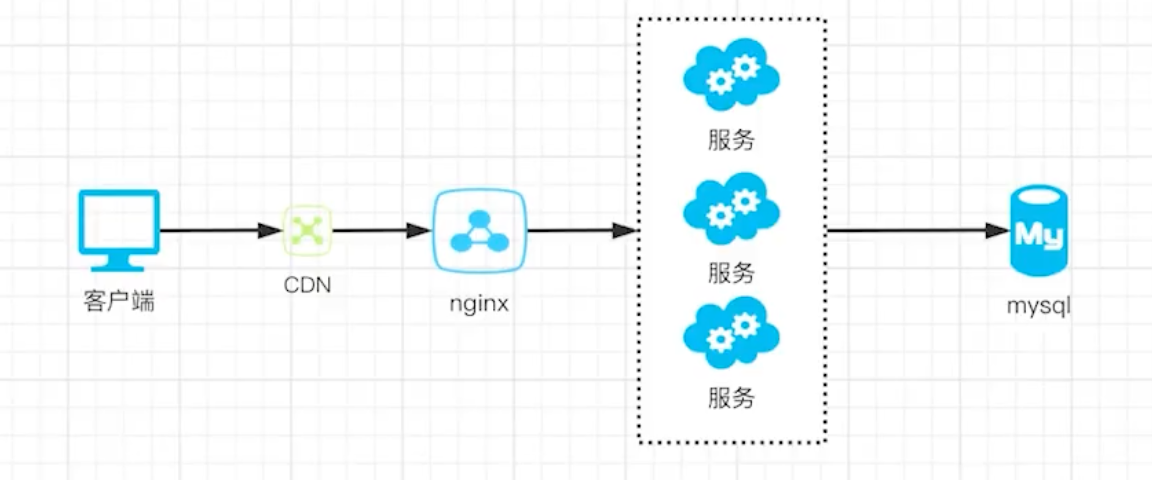
解决方案:
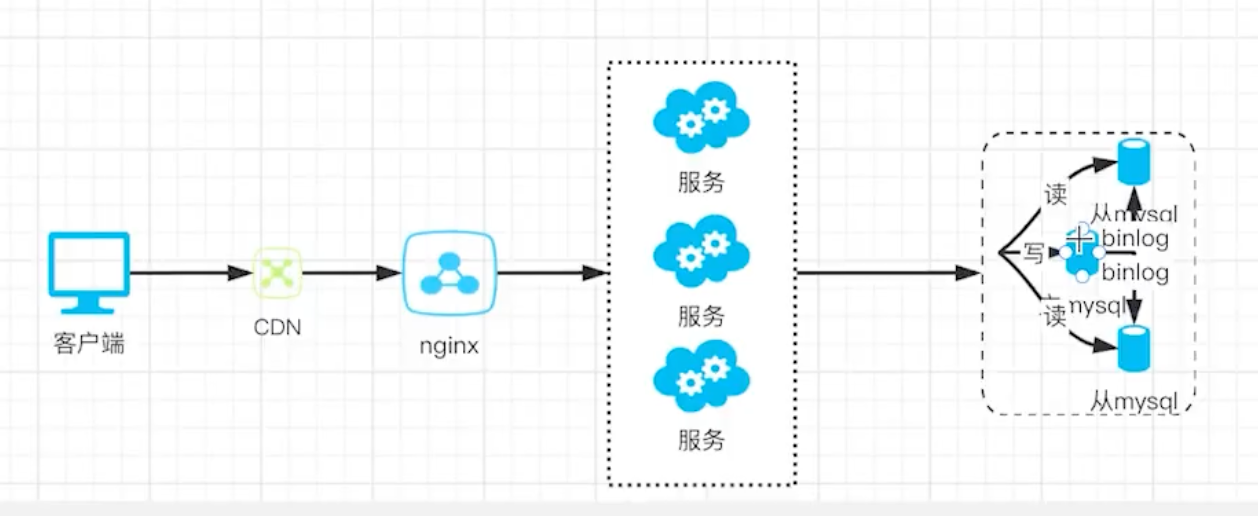
- 通过 Mysql binlog 实现主从复制
- 对不同用户创建不同读写权限,实现读写分离
- 分库分表
数据读写分离
数据的压力继续增大,数据库仍然是瓶颈。
解决方案:
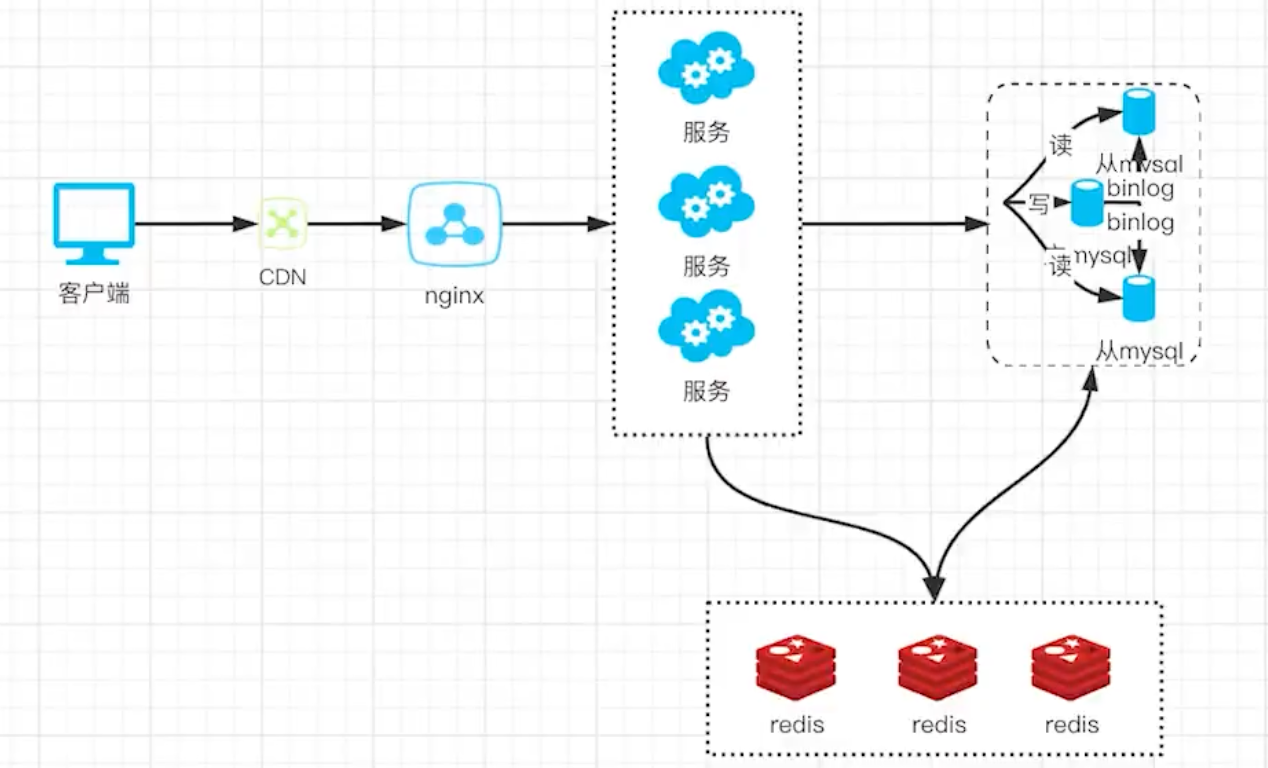
- 引入缓存系统,可以有效缩短服务的响应时间
缓存系统
随着流量继续增加,业务逻辑会变得越来越复杂,代码也会越来越复杂。
解决方案:
- 引入缓存系统,可以有效缩短服务的响应时间
消息队列
此时设计到这里,已经完全可以支撑百万级的数据。
Mysql 天生适合海量的数据存储,不适合海量数据的查询,所以此时数据的查询就成了瓶颈。
解决方案:
- 引入消息队列,异步、解藕、削峰
搜索引擎
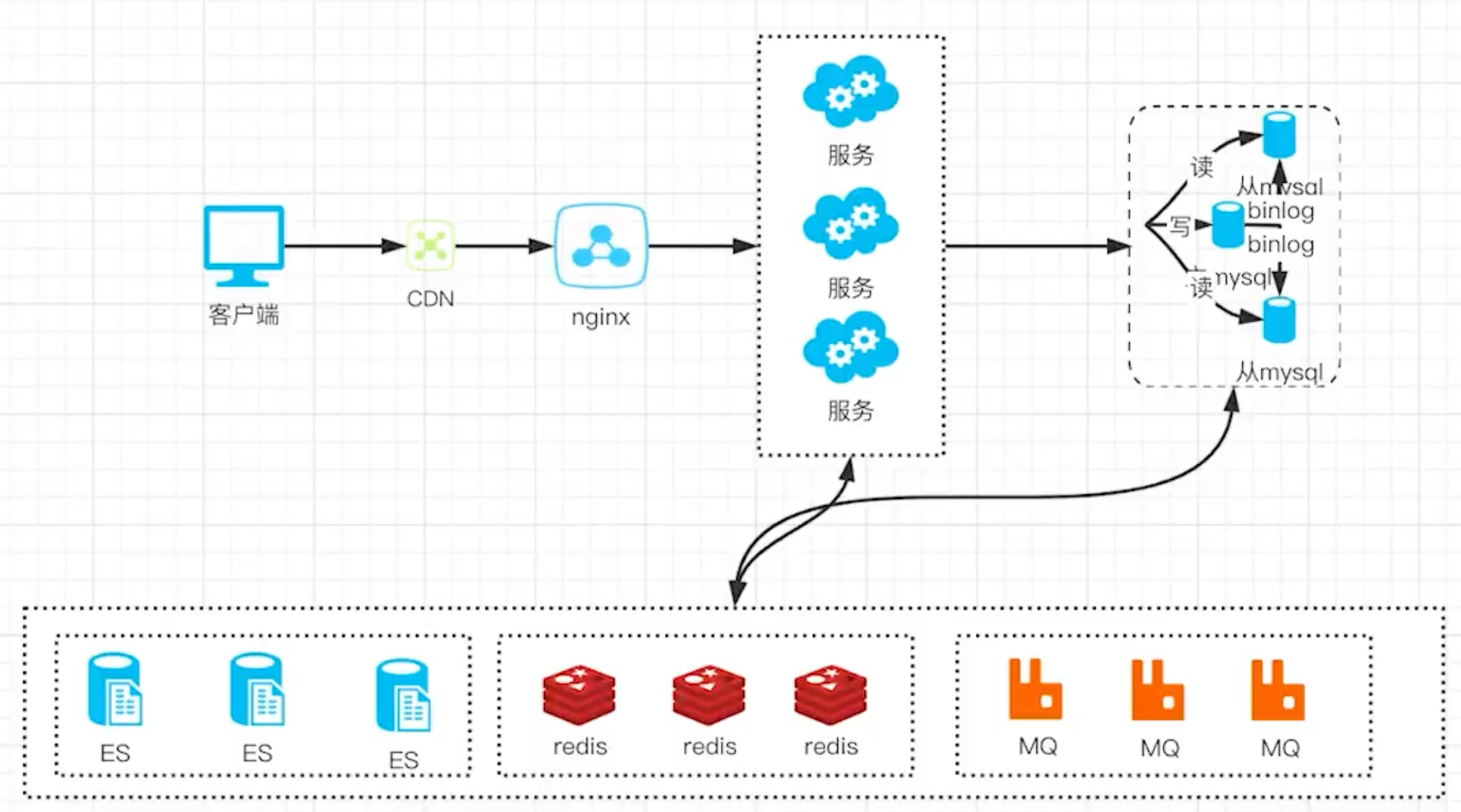
解决方案:
- 引入 ElasticSearch
引入搜索引擎之后,还可以对架构进行优化。
最后版本
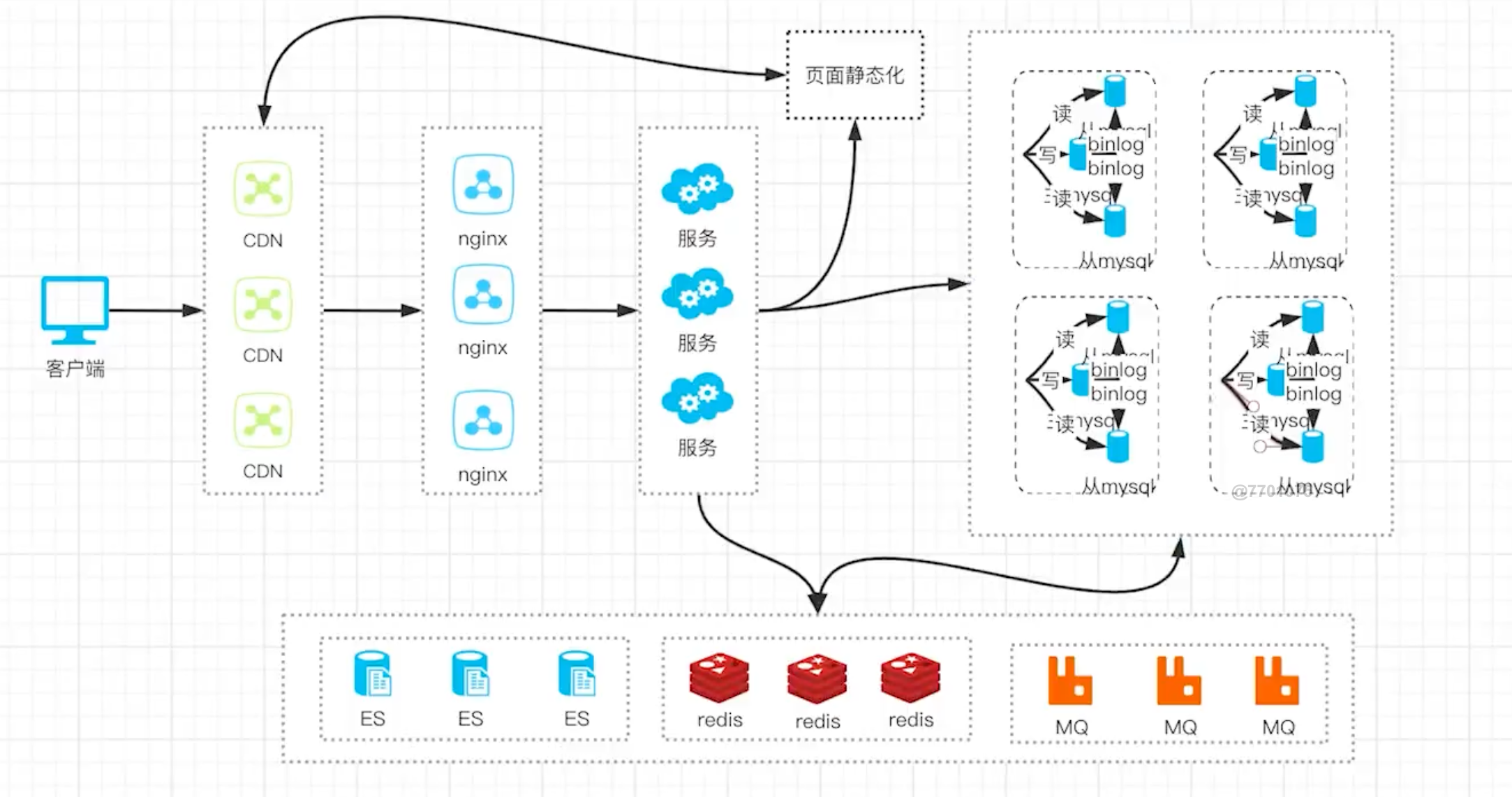
上面就是从最简单的单机到复杂集群的高并发演进之路,架构设计到最后,做好集群的话,支持亿级的数据是没有问题的。
其中的搜索引擎,消息队列等都是可以替代的。
高可用、高并发、高性能是一个很大的话题,它所涵盖的东西其实不止上面这些内容,其中每一个模块拿出来都可以扩展出很多知识点。
