Go 语言原生支持字符串。
作为一个站在巨人的肩膀上成长起来的现代编程语言。它继承了前辈语言的优点,又改进了前辈语言中的不足。这其中一处就体现在 Go 对字符串类型的原生支持上。
在C 语言中,并没有对应的字符串变量,不会像 PHP 语言专门有一个String 类型来存储对应的字符变量,那么是存储字符串的呢?
在C 语言中,是通过字符数组来存储字符串的:
1 | char c[] = "clang"; |
字符串是由字符组成的,对于计算机而言,字符串是由一个个字符组成的,而一个字符的大小是一个字节。
clang 这个字符串在计算机中,所占的大小是六个字节而不是五个,这是因为最后一个字符是由\0 结尾,也需要占用一个字节。
这样定义的非原生字符串在使用过程中会有很多问题,比如:
- 不是原生类型,编译器不会对它进行类型校验,导致类型安全性差
- 字符串操作时要时刻考虑结尾的
\0,防止缓冲区溢出 - 以字符数组形式定义的“字符串”,它的值是可变的,在并发场景中需要考虑同步问题
- 获取一个字符串的长度代价较大,通常是 O(n) 时间复杂度
- C 语言没有内置对非 ASCII 字符(如中文字符)的支持
这些问题都大大加重了开发人员在使用字符串时的心智负担。于是,Go 设计者们选择了原生支持字符串类型。
在 Go 中,字符串类型为 string。
Go 语言通过 string 类型统一了对“字符串”的抽象。这样无论是字符串常量、字符串变量或是代码中出现的字符串字面值,它们的类型都被统一设置为 string,比如上面 C 代码换成等价的 Go 代码是这样的:
1 | var c = "clang" |
原生支持字符串的优势
字符串类型数据不可变
这里并不是说不能为一个字符串类型变量进行二次赋值,而是不能改变字符的值:
1 | s := "golang" |
这样设计不用再担心字符串的并发安全问题。
没有结尾
Go 字符串中没有结尾 \0,获取字符串长度更不需要结尾 \0 作为结束标志。
并且,Go 获取字符串长度是一个常数级时间复杂度,无论字符串中字符个数有多少,都可以快速得到字符串的长度值(后面会解释)。
所见即所得
常常会需要对字符串进行拼接,因为转义字符的存在,较难控制好格式,在 Go 语言中,通过一对反引号原生支持构造“所见即所得”的原始字符串(Raw String)。
1 | var s string = ` ,_---~~~~~----._ |
在原始字符串中的任意转义字符都不会起到转义的作用。
Unicode 字符集支持
在之前的笔记中,已经提到过,Go 语言源文件默认采用的是 Unicode 字符集,Unicode 字符集是目前最流行的字符集,它囊括了几乎所有主流非 ASCII 字符(包括中文字符)。
对非 ASCII 字符提供原生支持,消除了源码在不同环境下显示乱码的可能。
字符串的组成
下面会从两个角度认识字符串:
- 字节视角:Go 字符串是由一个可空的字节序列组成,字节的个数称为字符串的长度
- 字符视角:Go 字符串是由一个可空的字符序列构成,字符串中的每个字符都是一个 Unicode 字符
字节视角
Go 语言中的字符串值也是一个可空的字节序列,字节序列中的字节个数称为该字符串的长度。一个个的字节只是孤立数据,不表意。
从字节视角看字符串的构成,它是不表示字符含义的(通俗点说就是,单从输出的字节是看不出来对应的是什么字符),这里输出的是字符串中的所有字节。
1 | var s = "中国人" |
因为一个中文汉字由 3~4 个字节组成,“中国人”是三个汉字,所以这里是 3 x 3 = 9 个字节。
字符视角
如果需要表意,则需要从字符视角来看了,也就是字符串是由一个可空的字符序列构成。
1 | var s = "中国人" |
在这段代码中,不仅输出了字符串中的字符数量,还输出了字符串中的每个字符。
Go 采用的是 Unicode 字符集,每个字符都是一个 Unicode 字符,每个字符都可以在 Unicode 字符集中找到,这里输出的 0x4e2d、0x56fd 和 0x4eba 就是 中国人 这三个汉字在 Unicode 字符集中的码点(Code Point)
可以在这个网站查找世界文字对应的 Unicode 码点。
那么,什么是 Unicode 码点呢?
因为 Unicode 字符集中的每个字符,按照一定规则,都被分配了统一且唯一的字符编号。所谓的码点,就是指将 Unicode 字符集中的所有字符“排成一队”,字符在这个“队伍”中的位置,就是它在 Unicode 字符集中的码点。
rune 类型与字符字面值
Go 使用 rune 这个类型来表示一个 Unicode 码点。rune 本质上是 int32 类型的别名类型,它与 int32 类型是完全等价的,在 Go 源码中我们可以看到它的定义是这样的:
1 | // $GOROOT/src/builtin.go |
由于一个 Unicode 码点唯一对应一个 Unicode 字符。所以可以说,一个 rune 实例就是一个 Unicode 字符,一个 Go 字符串也可以被视为 rune 实例的集合。我们可以通过字符字面值来初始化一个 rune 变量。
字符字面值
在 Go 中,字符字面值有多种表示法,最常见的是通过单引号括起的字符字面值,比如:
1 | 'a' // ASCII字符 |
字符串字面值
字符串是字符的集合,将表示单个字符的单引号,换为表示多个字符组成的字符串的双引号,就可以用来表示字符串字面值了:
1 | "abc\n" |
将单个 Unicode 字符字面值一个接一个地连在一起(示例中的第三行),并用双引号包裹起来就构成了字符串字面值。
不过,奇怪的是,为什么示例中的最后一行,与之前 Unicode 的码点对不上,反而很像从字节序列中输出的内容?
这是因为这个字节序列实际上是 中国人 这个 Unicode 字符串的 UTF-8 编码值。
UTF-8 编码方案
UTF-8 编码解决的是 Unicode 码点值在计算机中如何存储和表示(位模式)的问题。
既然码点可以确定一个 Unicode 字符,那么直接用码点不行吗?
确实可以,而且 UTF-32 编码标准就是采用的这个方案。UTF-32 编码方案固定使用 4 个字节表示每个 Unicode 字符码点,这带来的好处就是编解码简单,但缺点也很明显,主要有下面几点:
- 这种编码方案使用 4 个字节存储和传输一个整型数的时候,需要考虑不同平台的字节序问题
- 由于采用 4 字节的固定长度编码,与采用 1 字节编码的 ASCII 字符集无法兼容
- 所有 Unicode 字符码点都用 4 字节编码,显然空间利用率很差
针对这些问题,Go 语言之父 Rob Pike 发明了 UTF-8 编码方案。
和 UTF-32 方案不同,UTF-8 方案使用变长度字节,对 Unicode 字符的码点进行编码。编码采用的字节数量与 Unicode 字符在码点表中的序号有关:表示序号(码点)小的字符使用的字节数量少,表示序号(码点)大的字符使用的字节数多。
UTF-8 编码使用的字节数量从 1 个到 4 个不等。
- 前 128 个与 ASCII 字符重合的码点(U+0000~U+007F)使用 1 个字节表示
- 带变音符号的拉丁文、希腊文、西里尔字母、阿拉伯文等使用 2 个字节来表示
- 而东亚文字(包括汉字)使用 3 个字节表示
- 其他极少使用的语言的字符则使用 4 个字节表示
有关字符编码的更多知识,可以查看这篇笔记。
现在使用 Go 在标准库中提供的 UTF-8 包,对 Unicode 字符(rune)进行编解码试试看:
1 | // rune -> []byte |
utf8.EncodeRune:对一个 Unicode字符(rune) 进行 UTF-8 编码utf8.DecodeRune:UTF-8 解码,将一段内存字节转换成 Unicode 字符
好了,现在已经搞清楚 Go 语言中字符串类型的性质和组成了。
有了这些基础之后,就可以看看 Go 是如何实现字符串类型的。也就是说,在 Go 的编译器和运行时中,一个字符串变量究竟是如何表示的?
Go 字符串内部表示
在标准库的 reflect 包中,可以看到对字符串类型的定义:
1 | // $GOROOT/src/reflect/value.go |
string 类型其实是一个“描述符”,它本身并不真正存储字符串数据,而仅是由一个指向底层存储的指针和字符串的长度字段组成的。
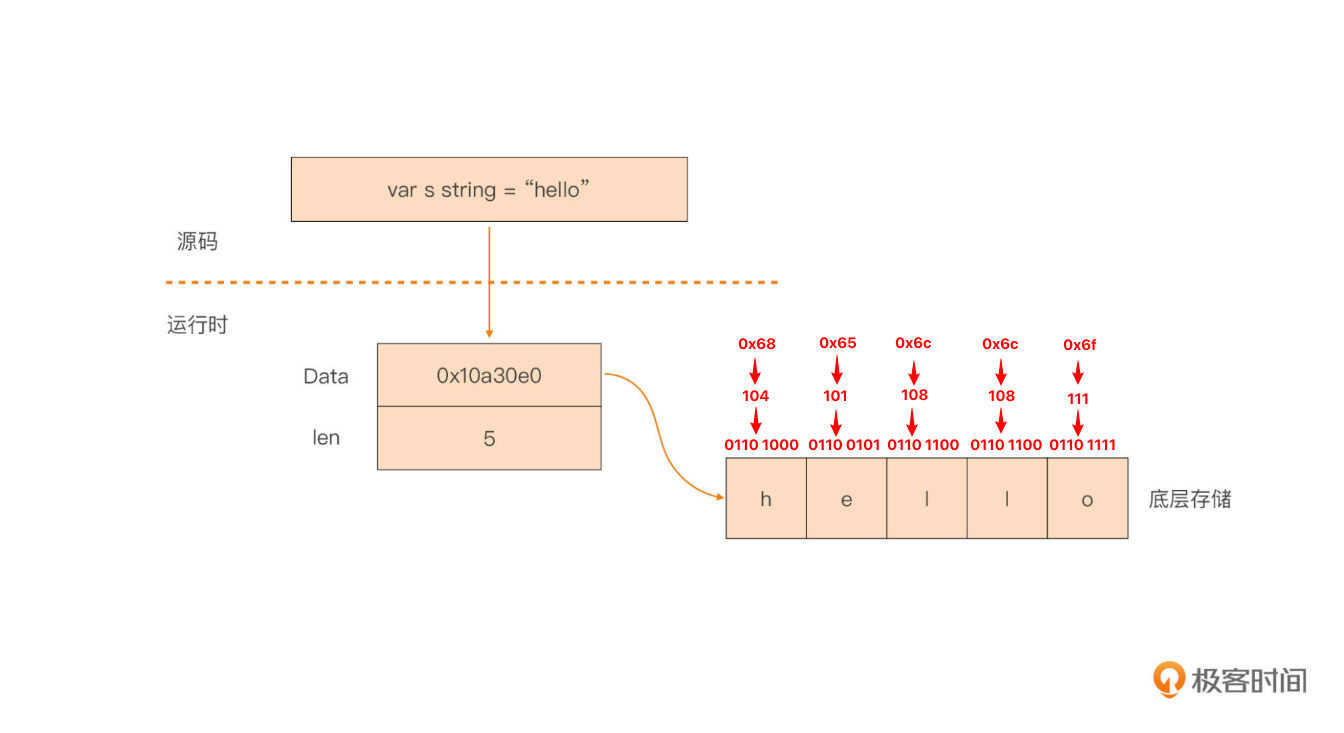
Go 编译器把源码中的 string 类型映射为运行时的一个二元组(Data, Len),真实的字符串值数据就存储在一个被 Data 指向的底层数组中。
1 | func dumpBytesArray(arr []byte) { |
这段代码利用了 unsafe.Pointer 的通用指针转型能力,按照 StringHeader 给出的结构内存布局,“顺藤摸瓜”,一步步找到了底层数组的地址,并输出了底层数组内容。
了解了 string 类型的实现原理后,就可以理解为什么获取字符串的长度的时间复杂度是常数。
以及可以得到这样一个结论:直接将 string 类型通过函数 / 方法参数传入也不会带来太多的开销。因为传入的仅仅是一个“描述符”,而不是真正的字符串数据。
总结
字符串类型作为基本数据类型之一,同样也是日常开发中高频使用的基本数据类型,从原理上看 string 类型,有助于对 Go 语言中的字符串有个完整而清晰的认识。
- 字符串底层是一个字节序列,不能按字节去遍历字符串,不能直接通过索引去修改字符串
- string 类型其实是一个描述符,由指向存储字符串数据内容区域的指针值和字符串的长度组成
- for range 迭代 string 采用的是字符视角,得到的结果是 Unicode 字符
- for 迭代 string 采用的是字节视角,得到的结果是 Unicode 字符经过 UTF-8 编码之后在内存中的表示
- Go 使用 rune 类型来表示一个 Unicode 字符的码点
