在浏览器中输入 www.0xbeace.com 这个域名,然后就能看到精美的页面了,这中间倒底发生了些什么呢?
其整个过程大致可以分为以下几个步骤:
- DNS 域名解析,寻找对应的IP 地址
- 根据这个IP 找到对应的服务器,建立TCP 连接(三次握手)
- TCP 建连之后,发起HTTP 请求
- 服务器响应 HTTP 请求
- 客户端接收数据解析并渲染页面
- 服务器关闭TCP 连接(四次挥手)
域名解析
以0xbeace.com这个域名为例,DNS 域名解析大致可以细分成以下几个小步骤:
- DNS 缓存(这里的缓存分为浏览器和操作系统)
- 本地域名服务器(Hosts 文件)
- 根域名服务器
- COM 顶级域名服务器
0xbeace.com域名服务器
域名解析一般就是按照该过程去查找,这里引用一张图(没找到具体出处),更加通俗易懂地解释了完整地解析过程。
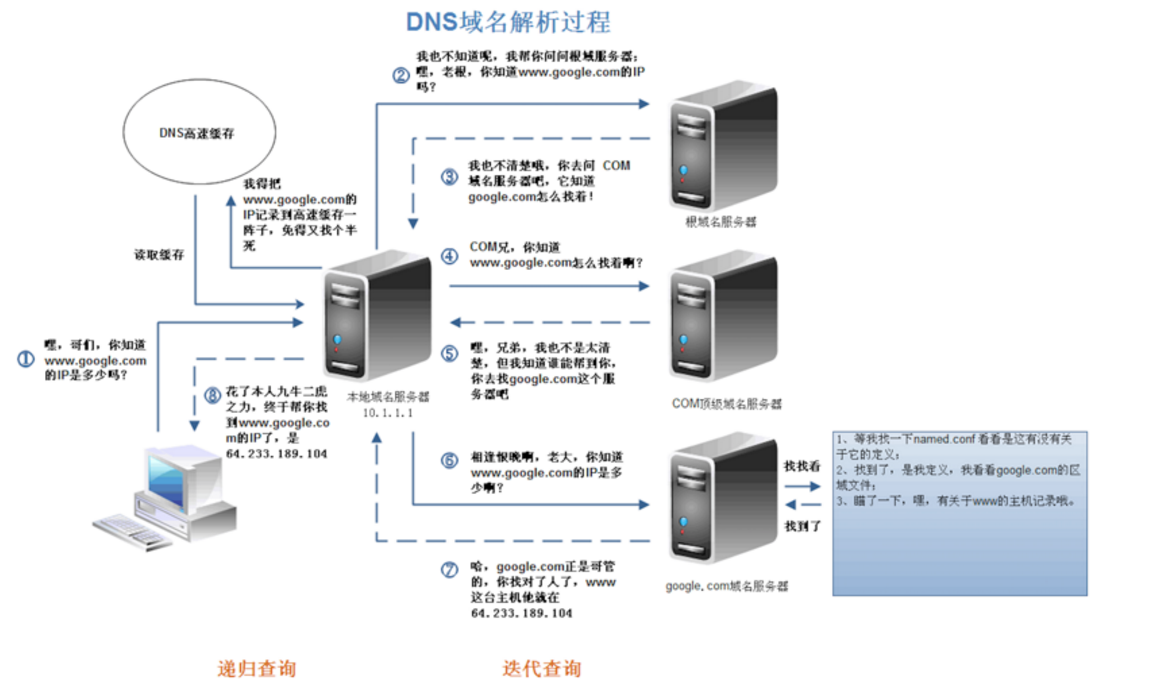
DNS 域名解析详细过程
TCP 建连
客户端发起请求
TCP 连接成功之后,就可以按照固定格式向服务器发起请求了。
一个完整的 HTTP 请求应该包含以下几部分:
- 请求行:用于描述客户端的请求方式(GET/POST等),请求的资源名称(URL)以及使用的HTTP协议的版本号
- 请求头:用于描述客户端请求哪台主机及其端口,以及客户端的身份信息(User-Agent)等
- 请求正文:客户端需要发送给服务端的数据
服务端响应请求
客户端成功发起请求之后,客户端接收请求并处理将结果响应至客户端。
一个完整的 HTTP 响应应该包含以下几个部分:
- 状态行:如:
HTTP/1.1 200 ok,分别表示 http版本 + 状态码 + 状态代码的文本描述 - 响应头:包含服务器相关信息
- 响应正文:服务器返回给客户端的数据
客户端渲染
这里以最常见的 .html 文件为例,当客户端接收到响应数据之后,便开始解析 HTML,如果遇到js/css这类静态资源,就会向服务器发起一个HTTP 请求,如果该请求的返回状态码是 304(已经缓存在本地浏览器了),就会直接从缓存中获取,否则就会开启新的线程去向服务器请求下载。
这时就用到了 keep-alive 这个特性,可以建立一次TCP 连接,发起多次 HTTP 请求。
然后浏览器再利用自己的内部工作机制,将HTML 与静态资源进行渲染,最后呈现给用户。
TCP 关闭连接
一般情况下,服务端向客户端完成一次请求,就会关闭TCP 连接,那么下一次又需要发起 HTTP 请求时,就需要再次建立一次TCP 连接了。
频繁建立/关闭连接,不仅增加了请求响应时间,还额外增加了网络带宽消耗,所以HTTP 协议为我们提供了一个可以保持TCP 的通用消息头:
1 | Connection:keep-alive |
至此一个完整的HTTP 请求就完成了。
其他问题
为什么HTTP 协议要基于TCP 来实现
这是因为TCP 是一个端到端的面向连接的协议,HTTP基于传输层TCP协议不用担心数据传输的各种问题(当发生错误时,会重传)。
